
Introduction
MuSig is a protocol which allows mutually distrustful parties to safely create aggregated digital signatures together. I highly recommend you read my MuSig article before diving into this one, as it lays down the context. If you’re already familiar with MuSig and Schnorr, carry on!
The MuSig protocol has several iterations:
- InsecureMuSig - An outdated and insecure 2-round version
- MuSig1 - The secure 3-round variant
- MuSig2 - The faster but slightly less secure 2-round variant
InsecureMuSig - the original form of MuSig - was proven insecure by Drijvers et al in 2018. The attack described in their paper depended on the fact that under InsecureMuSig, co-signers could manipulate the final aggregated nonce used for signing by submitting rogue nonces, computed as a function of their peers’ nonces. In response, the authors of MuSig amended their paper with a third nonce-commitment round of communication, thus preventing co-signers from providing rogue nonces.
This Blockstream article briefly summarizes the approach used by the attack, but only from the perspective an attack on an insecure implementation of MuSig1, in which nonces themselves are pre-shared before the message to sign is chosen. For a time, this article led me to mistakenly assume that it was the pre-sharing of nonces which made InsecureMuSig so insecure. However, that is not the approach used by Drijvers et al in their original paper. In the paper, Drijvers et al made no mention of nonce pre-sharing at all.
To my knowledge, there does not yet exist a full approachable explanation of how Wagner’s Attack broke InsecureMuSig. That is what I hope this article will be.
Bear in mind that I am no expert on Wagner’s Algorithm, but merely a tourist inclined to investigate algorithms which I find interesting. If you notice any mistakes, please suggest an edit on Github, or email me! I’d be very grateful for the help.
Notation
Just so we’re all on the same page:
| Notation | Meaning |
|---|---|
| The value |
|
| The sum of all |
|
| The base-point of the secp256k1 curve. | |
| The order of the secp256k1 curve. There are |
|
| A cryptographically secure namespaced hash function under the namespace |
|
| Sampling |
|
| Sampling |
|
| Concatenation of the byte arrays |
|
| The set of all integers from |
|
| “For every element |
|
| The order of (AKA number of elements in) set |
The Attack
The Setup
Alice, Bob and Carol have an aggregated public key
Carol has some evil message
Requirements
Carol will execute her dastardly attack by opening a number of concurrent signing sessions with Alice and Bob, and providing a set of carefully chosen rogue nonces. Rogue nonces behave similarly to rogue keys, which I highlighted in my MuSig article. If Carol learns Alice’s nonce
The “fully controls” part is particularly important. For Wagner’s Attack to work Carol must learn Alice and Bob’s public nonces before choosing her own, otherwise she cannot control the challenge
This is why InsecureMuSig was insecure: Unlike MuSig1, InsecureMuSig didn’t have a nonce-commitment phase. Co-signers simply exchanged their public nonces at will with no additional commitment phase or scrambling involved.
The Procedure
OK enough babbling. Let’s dive right in and see how Carol attacks this system.
Carol opens
concurrent signing sessions with Alice and Bob, in which she proposes to sign innocuous messages which Alice and Bob would be perfectly agreeable to signing. can be any power of two - higher is generally more efficient, but riskier for Carol. should approach but not exceed the maximum number of concurrent signing sessions that Alice and Bob can safely handle. Carol waits for Alice and Bob to share their public nonces
with her in every one of the signing sessions. Carol picks a nonce of her own which will protect her private key once the forgery is complete.
- Carol runs Wagner’s Algorithm to find
different curve points which hash to challenges which sum to an evil challenge .
is the “evil nonce” which will eventually be used for Carol’s forged signature. It is the sum of all of Alice and Bob’s nonces across all signing sessions, plus Carol’s own nonce . - Each
is hashed with the message to produce a challenge for signing session . - Through the wonder of Wagner’s Algorithm, the sum of all those
hashes equals another hash which Carol has chosen based on an evil message (which Alice and Bob never see).
- Carol calculates a set of rogue nonces
, one for each signing session.
The purpose of each rogue nonce
Alice and Bob do not know to avoid
Carol can thus convince Alice and Bob to sign
By now, perhaps you are starting to see why why Carol needed to open those
- Carol awaits the resulting
pairs of partial signatures from Alice and Bob.
Let
Alice and Bob will have computed their partial signatures as follows.
See how by selecting rogue nonces, Carol convinced her peers to sign the challenges
- Carol sums Alice and Bob’s partial signatures from those
signing sessions to create a usable forged signature which verifies under the aggregate key on Carol’s chosen message and evil nonce . Carol must add her own partial signature to complete the forgery.
This seems a bit too easy. How could this possibly work? Let’s expand
Group the private nonces all on the left, Alice and Bob’s private key terms in the middle, and Carol’s private key term on the right.
that doesn’t look like a valid Schnorr signature.
Not yet! But what if we…
Substitute All The Things
Here’s where the magic of Wagner’s Algorithm makes itself felt. Recall how Carol used Wagner’s Algorithm to find the the challenges
Wondering how Carol did this? We’ll get there eventually.
This relationship allows Carol to factor out
Oh look. Now we can merge the middle and right groups of terms by factoring out
This is starting to look suspiciously similar to a valid Schnorr signature.
what about that first term with the sum of the secret nonces?
Remember how we defined the evil nonce
Although Carol doesn’t know the actual value of
We can substitute
We can further simplify by denoting the hypothetical aggregated private key as
The forged signature
If you understand everything above, then congratulations: You’ve just grasped the clever attack that forced some of the most famous cryptography experts in the Bitcoin community to backtrack and rework their original InsecureMuSig algorithm. You could close the page here, and give your brain a little “good job!” affirmation for grasping such an outlandish cryptographic attack.
But the perversely curious among you may wonder,
how did Carol find those curve points
? how did she know they would result in challenges which sum to
?
If these questions are eating at you, read on to learn more. But beware! Here be dragons…
Wagner’s Algorithm
From an attentive reading of the attack procedure, I hope you’ll agree that the secret sauce seems to come in the form of some black box which I referred to as Wagner’s Algorithm. Carol used it to find a set of points that she used to fool Alice and Bob into signing challenges which Carol chose. This resulted in a forgery.
This black box is an algorithm originally described in David Wagner’s 2002 paper on the Generalized Birthday Problem in which he demonstrates a probabilistic search algorithm which can be used to find additively related elements in lists of random numbers.
what the hell does that mean?
Let’s back up a bit and sketch out the high-level game plan here. Wagner’s original paper is quite dense. I made several attempts at this section of the article before landing on what I believe to be a reasonably intuitive but also succinct description of Wagner’s Algorithm. It will help if I outline our approach before I describe the algorithm itself.
- First we will review some principles of probability theory which we’ll need to make use of.
- We’ll generate a bunch of lists of random hashes.
- We’ll define a merging operation to merge pairs of lists together into another list of about the same size as either parent list.
- Those merged lists will contain sums of hashes which are close to zero mod
. - We’ll repeat this merging operation recursively in a tree-like structure until the hash-sums approach zero.
- We’ll follow pointers back back up the tree to the original lists, and find inputs which, when hashed, should sum to any number we want mod
.
Probabilities
Before we dive into a probability-driven algorithm, let’s review some probability theory!
Probability of Modular Sums
Imagine you have three D6 dice
Assuming all the dice are evenly weighted and rolled independently, there are
| 1 | 1 | 2 |
| 1 | 1 | 3 |
| 1 | 1 | 4 |
| 1 | 1 | 5 |
| 1 | 1 | 6 |
| 1 | 2 | 1 |
| 1 | 2 | 2 |
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 1 | 2 | 5 |
| 1 | 2 | 6 |
| 1 | 3 | 1 |
| … | … | … |
| 6 | 6 | 5 |
| 6 | 6 | 6 |
This works out such that each possible sum mod 6
There’s nothing special about a modular sum of zero here. You can pick any constant
Imagine rolling one die. That event has an exact
Roll a second die and add it to the first. This adds some
Expected Values
The expected value of some variable is the value you can expect it to hold on average. It can be calculated by taking a weighted sum of every possible outcome value, multiplied by the probability of that outcome.
For example, if you were to roll a six-sided die
The Linearity of Expectation property of Probability Theory tells us that the expected value of a sum of random variables is simply the sum of their respective expected values. Sounds weird when you say it like that, but an example should help.
Roll two six-sided dice and sum them together. What’s the expected value of that sum? It’s the sum of each die’s own expected values, i.e.
Here’s another way to conceptualize Linearity of Expectation. You roll a six-sided die 100 times. How many times would you expect to roll a five?
The probability of rolling a five on any given roll is obviously
Therefore, after 100 rolls you can expect about 16 or 17 dice to roll a five (or any other number from 1 to 6, for that matter).
Review done! Not so bad, right? On to Wagner’s Algorithm.
List Generation
In our effort to forge an aggregate signature, the main thing Carol needs is some set of nonces
If Carol can find such a set of nonces, she can use it to produce a forged signature by sending rogue nonces to Alice and Bob as described earlier.
The catch is that Carol can’t predict the output of
Wagner’s Algorithm can do exactly this. It works by finding patterns in lists of random numbers. Turns out, even perfectly random data can still behave predictably if we massage the data properly.
So first things first - We need to generate those random numbers. In our case, we aren’t using truly random numbers. Instead we will use the pseudo-random hashes generated by
We’ll run
- the curve points
- the aggregated public key
- the benign messages
- the evil message
(the one which lets Carol steal from Alice and Bob if she can forge a signature on it) - the evil nonce
Carol cannot influence the aggregated pubkey
As we discussed previously, Carol can use rogue nonces to trick Alice and Bob into using any point
Let
Carol generates
* Notice how I’ve denoted the candidate nonces
Carol generates the last list
This is part of the setup process to ensure we end up with a set of hashes which sum specifically to
how is the list length
chosen?
Patience. I’ll return to that one in a bit.
Carol should store pointers back to the candidate nonces
The lists of hashes will look like this.
| Lists | |||||
|---|---|---|---|---|---|
| … | |||||
| … | |||||
| … | |||||
| … | … | … | … | … | … |
| … |
In the above table, the
It doesn’t actually matter whether Carol knows the discrete log (secret key) of each aggregated nonce
Solution Counting
Let’s simplify: Say we have two lists of hashes
If we were to merely sample 2 random numbers
Why? Recall the dice example: Since we’re summing
With a totally random approach like that, we’d need to attempt (on average)
If our two lists
The product of the length of both lists
By the Linearity of Expectation property of Probability Theory, we can infer the expected number of solutions in
This tells us pretty clearly that we want
If instead of two lists, we had
The probability of a random set of hashes among those lists summing to
Assume each list has the same length
Then the total number of possible permutations would be
If we want on average 1 solution to exist among these
This brings the expected number of solutions among
As for actually finding the solution… The output of the hash function
Search Strategy
If we do a naive sequential search of the lists
We’re assuming
So what’s a cypherpunk to do?
A classic trick of algorithmic efficiency is to break down a complex task into smaller and simpler ones.
It is evidently too difficult to find a solution when hashes are all evenly distributed among
It would be easier if we only had to look for solutions distributed among a smaller range than
Let’s explore a particular example of Wagner’s Algorithm where
Why sum to
We will build a binary tree, and break the problem into smaller chunks at each distinct height

After building the final root node list
Merging The Leaves
Perhaps we could merge two leaf lists
When merging two parent lists
- Elements in the child list should be distributed across a significantly smaller range of possible values than the elements in the parent lists.
- Elements in the child list should be the sum of two elements from the parent lists. Each child list element should maintain pointers to the two elements in the parent lists which created them.
Our approach to merging will be to iterate through every combination of candidate elements
How big should that range be?
Let’s parameterize the filter range
We don’t know what that interval is yet, but we can deduce what it should be.
Assume the two leaf lists
Since both parent lists have length
If we independently roll this probability once for each unique pair in lists
We already know that the probability of two elements
Intuitively it should make sense that the probability then becomes
We can use this relationship to compute how large the initial filter range
Booyah! A filter range of size
For a range of size
The range
To rephrase more succinctly: If we make
The
Furthermore, if we add together any two elements sampled from
Merging the Children
What about for other heights?
When we merge the lists
In general, if we want to expect
This gives us a generalized formula for the
By repeating this procedure, merging lists in a tree-like pattern, we can gradually reduce the domain among which elements in each merged list are distributed.
| Height | Filter Range Size |
|---|---|
| … | … |
Remember as well that for every pair of elements
If a merge operation ever outputs an empty list, this is a failure condition and it means we need to retrace our steps, starting over with new randomly generated leaf lists. If we merge an empty list
Finding the Solution
Remember our goal is not just to shrink the domain but to find a tangible solution. Thankfully, as we cinch the domain of elements closer around zero, we become exponentially more likely to find solutions. By merging lists, we are reducing the number of lists - thus reducing the number of permutations we have to check - but also we are increasing the probability that any set of elements
We will ultimately need to perform a different operation
The obvious way to do this is to define the operation
More efficiently, we could perform
Consider the following lists:
If
Returning to our
For efficiency, we don’t actually want to evaluate the whole tree top-to-bottom like this, because doing so would require that we keep unnecessary lists in memory during the procedure, which might be expensive if those lists are large, or if there are lots of lists. It would be better if we only load the lists into memory (or generate them) when needed.
Thanks to the tree structure of the algorithm, we can evaluate the merging operations in a deferred sequence to reduce memory requirements. We could discard the elements of parent lists if they are no longer referenced by the child lists they are merged into.
For our
Leaf lists like
This way, we don’t have to store so much data in memory at once. Instead we only have to store a maximum of 4 lists at a time in this example: two in storage and two in working memory (to perform merge operations). For larger values of
List Length
We still have yet to fully understand how to choose our list length
When we build the root list
The height of the penultimate lists will be
This makes sense for our
Thus, we want
And we can make use of that to compute what
In general, we can choose the list length
In english,
Full Description
Above I’ve tried to walk through the steps of Wagner’s Algorithm in detail, justifying each step in an attempt to make it seem more approachable.
In this section, I’ll provide a bare description of the algorithm itself applied to InsecureMuSig, and omit the full reasoning behind each operation.
Fix the modulus
and the desired sum . Choose
, which describes how many lists we want to search, and how many concurrent signing sessions Carol will need to open with Alice and Bob. Compute the list length
.
- Define the list-generation procedure for lists
, by sampling randomized inputs per list.
For the last leaf list
For better memory efficiency, these lists should only be generated once they are needed. Each hash
- Define the merge operation
for a given height . This operator merges two lists into a new list at height by summing each combination of two elements, one from each list, modulo and including the sum in its output list if the sum falls within an inclusive range , wrapping modulo .
Every element
- Define the join operation
which will be used to construct the final root list at the maximum tree height . This operator returns a list composed solely of zeros which also have pointers to the parent elements which were summed to create them.
- Begin merging lists.
- Start by generating the first two leaf lists
and , and merge them as at height . - Generate lists
and . Merge them as . - Merge these two lists
at height . - Generate new lists
and .
Continue in this fashion, proceeding to the next height whenever possible, generating new leaf lists and merging them as required, until we have the two penultimate lists at height
If a merge operation ever results in an empty list, discard this branch of the tree and start over with freshly generated leaf lists.
- Join the penultimate lists
and with the join operator .
If
If
contains at least one element, follow its pointers back up the tree to the hashes in the leaf lists. The result will be a set of hashes such that . Follow the pointers from the leaf elements to find the curve points
which were hashed to construct each element. Since the last leaf element was constructed by subtracting from the actual challenge, this means the set of nonce points will result in signature challenges which sum to .
- Carol can now provide rogue nonces to Alice and Bob so that
are used as the aggregate nonces in each of the signing sessions, as discussed before.
Performance
Let’s analyze the computational complexity of Wagner’s Algorithm.
- At each list-merging operation (
), we must perform simple addition operations. - At the root node at height
, we perform a join operation which uses computations. These operations are insignificant next to the rest of the computations though, so we can safely ignore them. - We must perform
merging operations at height , then merging operations at height , then operations at , and so on. - This means we perform
merges, for a total of simple addition operations.
The sequence
The sum of a finite geometric series starting at
Because
A quick sanity check and our formula seems to work:
Thus in total, we perform
Optimizations
There’s an easy optimization which boosts the speed of Wagner’s Algorithm by at least one order of magnitude.
The bulk of the work occurs when adding together every combination of elements
1 | def merge(L1, L2): |
The complexity thereof is
Remember that
One option would be to sort the list
Observe how for any given
Any values in
If
As an example, consider a case where:
We are merging two lists like so:
- First, we loop through
and encounter the element . - Compute the minimum viable value for
as . - Since
is sorted, we can binary search it to quickly find where we could expect to find if it existed in . It would be at the very end of though, so we wrap around to the beginning of and begin our search there at . , which does not fall into the range . We can now discontinue our search for a partner sum for . This checks out, because indeed there is no number which would sum with such that .
- Compute the minimum viable value for
- Continuing our loop through
, we encounter the element . - Compute the minimum viable value for
as . - Binary search
to find where would sort into . We find the index for the next highest value in : . - Beginning our search here, we find that
which does fall within . We add to the output list and continue looping forward through . - We hit the end of
, but once again we wrap around to the beginning of . We encounter the element . does not fall within the filter range. We discontinue the loop here and move on to the next element of . Again this checks out, because no can provide .
- Compute the minimum viable value for
In Python, this might look something like so:
1 | from bisect import bisect_left |
This new merge operation has significantly lower complexity.
- It requires one sorting operation per merge, which can be done in
time with an algorithm such as heapsort, quicksort or merge-sort. - Once
has been sorted, we loop through for a total of iterations. - On each iteration, we perform a binary search of
in time. We then add an average of 1 element to the output list (since we expect to have elements), and also perform one extra check which tells us when we run out of useful elements in .
In total, our new merge operation algorithm requires
computations. It runs in
This is a big improvement over the
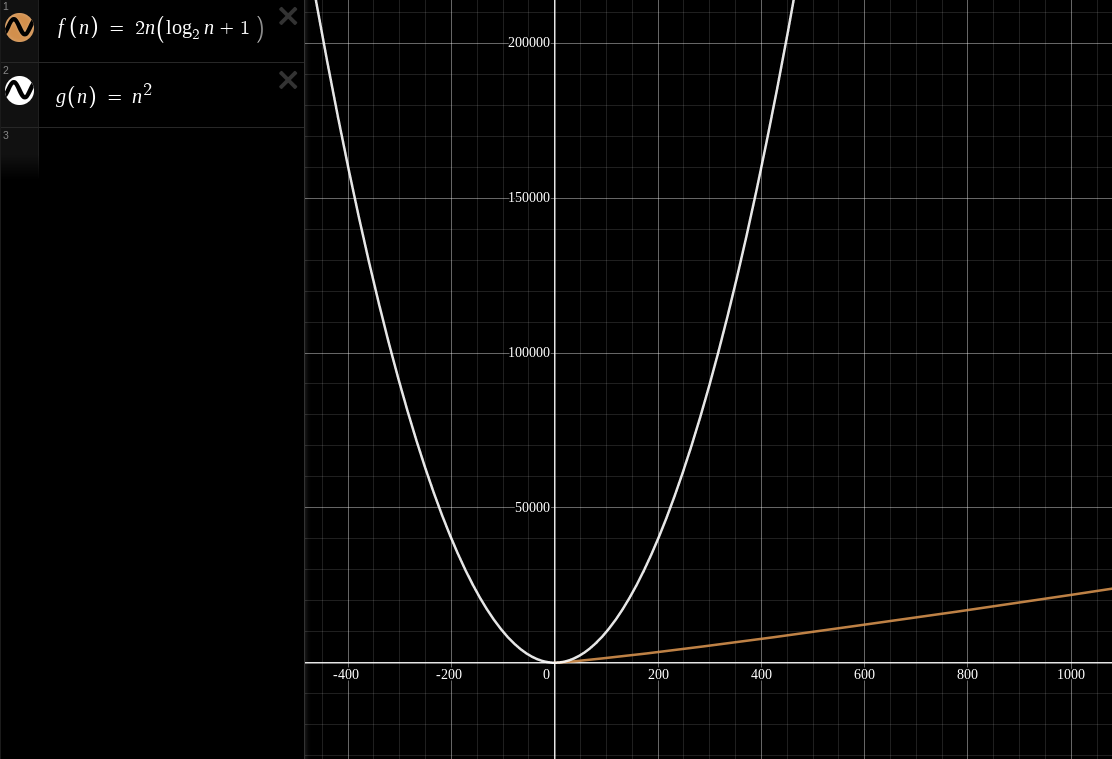
To put this into perspective, merging two lists of length
Since we are performing
Choosing
If we fix
Does fewer elements per list result in fewer computations overall? Is there some ideal number of lists which optimizes the amount of computation required to find a solution? In our case, we can set
The total work we need to do is
But however nerdy I may be, I am also adverse to pointless effort. It would be much easier to simply guess and check every plausible value of
1 | from math import log2, inf |
1 | k = 4; computations required: 16831834955285952201643524096; change: +nan% |
Looks like for secp256k1, the best case for computation time of Wagner’s Algorithm is
Realistically, Carol may want to set
Normal Distributions
There is one odd detail of Wagner’s Algorithm which still mystifies me.
If we sample two random elements
This is because the filter range
Thus, for any pair
To better understand this, imagine a smaller-scale hypothetical example where
| + | -5 | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|---|---|---|---|---|
| -5 | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
| -4 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 | 0 |
| -3 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 | 0 | 1 |
| -2 | -7 | -6 | -5 | -4 | -3 | -2 | -1 | 0 | 1 | 2 |
| -1 | -6 | -5 | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 |
| 0 | -5 | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 |
| 1 | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 | 5 |
| 2 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 4 | -1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
As you can see,
Notably this does change the probability math when computing how to define our next filter range
Strangely however, Wagner’s original paper makes no mention of this normal distribution. Wagner only illustrates the generalized form of his algorithm for
We can also apply the tree algorithm to the group
where is arbitrary. Let denote the interval of elements between a and b (wrapping modulo m), and define the join operation to represent the solutions to with . Then we may solve a 4-sum problem over by computing where and . In general, one can adapt the -tree algorithm to work in by replacing each operator with , and this will let us solve -sum problems modulo about as quickly as we can for xor.
In his paper, Wagner focused on solving what he dubbed the
Peculiarly, Wagner’s Algorithm still seems to work for large values of
Implementation
To prove to myself that this absurd-seeming procedure actually works, I wrote up a pure Python implementation of Wagner’s Algorithm. Click here to view the code on Github.
You can install and use it with pip install wagner.
1 | import random |
My code demonstrates that although the attack is plausible, it is still very hard to pull off. Not to disparage my performance optimizations, but the procedure is quite slow for large values of
Beyond this, the procedure is too slow to execute a real-world attack. After opening her
However, simply because my code does not compute solutions fast enough doesn’t mean the attack is infeasible. There exist many much stronger computers out there, and I have barely scratched the surface of the possible optimizations one can make to Wagner’s Algorithm. Not to mention I wrote my implementation in one of the slowest programming languages in town, and made no attempts whatsoever at parallelization. With enough rented cloud computing power, a faster language like C or Rust, and a cleverly optimized implementation, it would certainly be plausible to execute this attack.
Conclusion
Thankfully, the whole attack has been made obsolete against the real MuSig, due to the nonce commitment round which was introduced in the updated MuSig protocol. Without the option to choose rogue nonces, Carol cannot control the challenges.
However, as Blockstream’s Jonas Nick writes, Wagner’s Attack is definitely still applicable to MuSig in some edgecases though. It pays for devs to really understand how this attack works, so that hopefully we can avoid reintroducing the same vulnerability when creating new protocols or when optimizing existing systems.
The subtle math behind the attack is fascinating. It goes to show that however experienced one might be, the true test of a cryptosystem occurs when it is exposed to a critical and observant community. It is absolutely essential for experts to attack each other’s systems. There’s simply no way for any one person (or even a group of people) to collectively hold in their mind all the myriad ways their system could be attacked.
In cryptography, a solid proof is like a well-forged sword… but rigorous peer review is the grindstone, and time is the foot which effects the sharpening.